대학생 시절 2건의 딥러닝 프로젝트를 진행해서 다시 보면 쉽게 할 줄 알았는데 정신이 나가는 현상의 반복이었다..
딥러닝 공부를 하게 되면 무조건 실습하게 되는 mnist부터 다양한 딥러닝 학습 방법까지 확인해보았다.
Tensorflow는 구글이 공개한 딥러닝 라이브러리, Keras는 Tensorflow의 고수준 API이다.
딥러닝(Deep Learning)
딥러닝이란? 여러 층을 가진 인공신경망(Artificial Neural Network, ANN)을 사용하여 데이터를 학습하는 방식이다.
인간의 두뇌에서 영감을 얻은 방식으로 인간의 뇌를 흉내내어 시스템이 인간의 개입 없이 더 정확하게 식별하고 작업을 수행한다. 딥(Deep)이란 표현을 쓰는 이유는 층을 연속적으로 쌓아 올렸기 때문, 즉 여러 신경망 레이어와 복잡하고 이질적이며 대량의 데이터를 포함하기 때문이다.
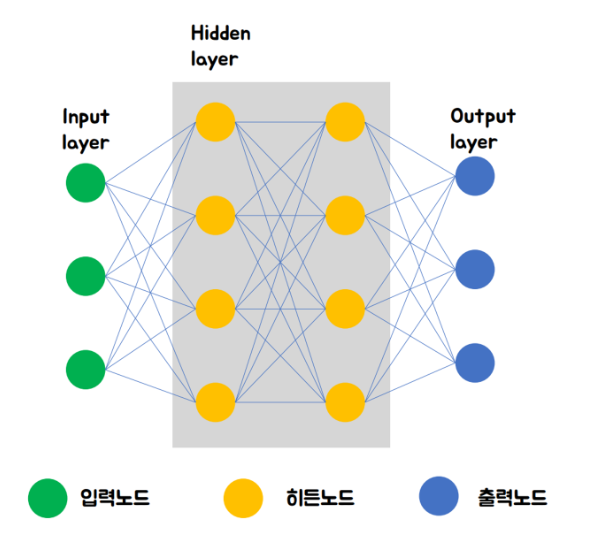
인공신경망(ANN)은 생물학적 두뇌의 뉴런을 기반으로 모델링된 네트워크이다. 인공뉴런은 노드(node)라고 하며, 여러 레이러로 클러스트화 되고 병렬로 작동한다.
딥러닝 인공 신경망(neural network)
위에 설명과 같이 인공신경망은 인간의 두뇌로 부터 영감을 받아 두뇌의 신경 세포, 즉 뉴런이 연결된 형태를 모방한 모델이다. 인공신경망(ANN)을 간략히 신경망(neural network)라고도 하며 뉴런이 서로간에 신호를 보내는 방식을 모방한다.
아래 사진을 보면 딥러닝의 내부작업은 사람이 직접 관여할 수 없고 숨겨져 있다고 한다. 이를 블랙박스라고 칭하며 블랙박스는 내부 작업의 어떤 이해없이 입력과 결과의 측면으로 볼 수 있는 시스템이다.
즉 입, 출력만 나올 뿐 그 내부 작업은 명확하지 않다는 것이다.
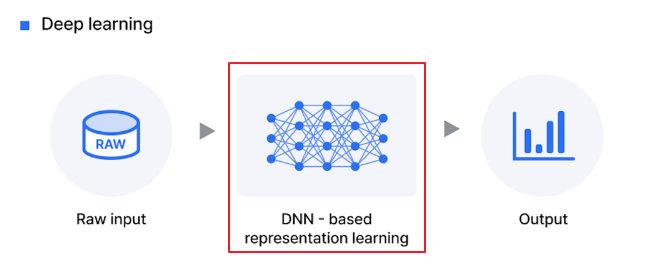
블랙박스 현상의 발생 원인은 왜 일까?
그 이유는 딥러닝에서 히든레이어(Hidden layer)를 분석하는 것이 너무 어렵기 때문이다. 히든 레이어 안에 수 많은 히든 노드들이 엉켜서 복잡하게 쌓여 있는데 이런 레이어가 수십개씩 존재한다고 하면 내부 파악은 불가능한 것이다.
실습1 - 간단한 신경망 만들기
다음 실습은 입력 데이터와 출력 데이터의 관계를 학습하여 파악한 후 새로운 입력값을 입력했을 때 출력 값을 예측하는 모델을 만들었다.
1. Neural Network 구성
Tensorflow의 가장 간단한 Neural Network 구현.
import tensorflow as tf
from tensorflow import keras
import numpy as np
model = keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])- tf.keras (tensorflow.keras) : Keras API 모듈
- Sequential() : Neural Network의 각 층을 순서대로 쌓을 수 있도록 한다. → Sequential 많으면 많을수록 여러층으로 되어있다는 뜻
- Dense() : (완전히 연결된) 하나의 뉴런층을 구현.
- units : 출력 노드의 개수 → units=1는 출력 노드를 1로 설정 → 출력값 1개
- input_shape : 입력 데이터의 형태를 결정 → input_shape=[1] → 입력 개수 설정 → 입력값 1개

2. Neural Network 컴파일
Neural Network 모델을 컴파일하는 과정에서는 모델의 학습에 필요한 손실함수 (loss function)와 옵티마이저 (optimizer)를 결정.
- 손실함수(loss function) : 예측이 얼마나 잘 맞는지 측정하는 역할
- 옵티마이저(optimizer) : 더 개선된 예측값을 출력하도록 최적화하는 알고리즘
model.compile(loss='mean_squared_error', optimizer='sgd')
3. Neural Network 훈련
Sequantial 클래스의 fit() 메서드는 주어진 입출력 데이터에 대해 지정한 횟수만큼 Neural Network를 훈련.
- 에포크(epoch) : 주어진 데이터를 몇 번 훈련할지 정하는 단위
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model.fit(xs, ys, epochs=500)
4. Neural Network 예측
Sequantial 클래스의 predict() 메서드를 사용하면 특정 입력에 대해 Neural Network가 출력 (예측)하는 값을 얻을 수 있다.

pred = model.predict([5.0])
print(pred)
# 5입력 시 출력값 : 8.993531
비록 작은 오차가 있지만 간단한 Neural Network는 어떤 입력 x에 대해서 대략 2x - 1를 출력하도록 훈련이 되었다.
이렇게 입력값과 출력값을 통해 모델이 상관관계를 학습하여 다음 입력값에 대한 결과를 도출한다.
실습2 - MNIST (숫자 이미지 판별)
1. 환경 준비
Tensorflow와 필요한 라이브러리를 import.
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
2. 데이터 준비

위의 이미지와 같이 MNIST 데이터 셋은 0~9까지 10가지로 분류될 수 있는 손글씨 숫자 이미지 70,000개로 이루어져 있다.
각 이미지는 28*28 픽셀로 구성되고 각 픽셀은 0~255 사이의 숫자 행렬로 표현된다.(RGB 단위)
MNIST 데이터 셋을 load하고 훈련 세트와 검증 세트로 분할한다. 그 후 입력 데이터를 정규화하여 0과 1사이의 값으로 변환한다. (0과 1이하 숫자로 변환 이유 → 아무리 곱해도 0~1 사이)
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# x_train은 여러가지 픽셀 단위 데이터 정보값 존재
# y_train은 결과(0~9 숫자) 존재
왜 255로 나눌까?
- 안정적인 학습이 목표: 이미지 픽셀값이 크면 처리에 어려움. 따라서 0과 1사이 값으로 변경
- 빠른 학습: 작은 값으로 데이터를 바꾸면 학습 속도가 빨라진다.
- 계산 문제 방지: 큰 숫자를 계속 계산하다보면 컴퓨터가 계산을 틀릴 확률 높아짐
- 더 좋은 결과 도출
3. 모델 구성
신경망 모델을 구성.
# flatten: 행렬로 되어있는 형태를 1차원으로 수정하는 작업 -> 컴퓨터가 처리하기 쉽게 만들기 위해서
model = Sequential([
Flatten(input_shape=(28, 28)), # 1. 28*28의 행렬을 1차원으로 변환 # 입력레이어 -> 2차원에서 1차원으로 변환
Dense(128, activation='relu'), # 2. relu라는 옵티마이저를 통해서 128개의 은닉층으로 구성된 은닉레이어를 생성
Dense(10, activation='softmax') # 3. 타켓의 개수 지정(0~9), softmax 옵티마이저를 사용하여 출력레이어 생성 -> 0~9까지의 숫자를 예측하는 것
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
4. 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
5. 모델 실행
훈련 데이터를 훈련하고 검증 데이터로 검증.
history = model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_test, y_test))
- x_train, y_train : 훈련 데이터셋의 입력 x, 레이블 y로 x_train = 이미지 데이터, y_train = 숫자 레이블.
- epochs : 반복횟수, 에폭이란 전체 훈련 데이터셋을 한번 통과하는 것. 에폭 수 = 5라면 전체 훈련 데이터 셋은 모델에 총 5번 통과.
- validation_data : 모델 성능 평가
- batch_size : 모델을 한번 엡데이트할때 사용하는 샘플의 수. 보통 4와 8의 배수로 설정(램의 크기가 4G, 8G, 32G..)

6. 결과 시각화
#결과 시각화 정리
import numpy as np
# 테스트 데이터를 사용하여 예측 수행
predictions = model.predict(x_test)
def display_prediction(index, predictions_array, true_label, img):
plt.figure(figsize=(6,3))
# 이미지 출력
plt.subplot(1, 2, 1)
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img[index], cmap=plt.cm.binary)
# 예측 결과 출력
predicted_label = np.argmax(predictions_array[index])
if predicted_label == true_label[index]:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(predicted_label,
100*np.max(predictions_array[index]),
true_label[index]),
color=color)
# 예측 확률 막대그래프 출력
plt.subplot(1, 2, 2)
plt.bar(range(10), predictions_array[index], color="#777777")
plt.ylim([0, 1])
plt.xticks(range(10))
plt.ylabel('Prediction Probability')
plt.xlabel('Predicted Value')
plt.tight_layout()
plt.show()
# 첫 번째 예측 결과 시각화
display_prediction(100, predictions, y_test, x_test)
# 두 번째 예측 결과 시각화 (실제로 코드를 실행할 수 있다면 이 부분을 주석 해제하여 실행하세요)
# display_prediction(1, predictions, y_test, x_test)
'모두의 연구소(오름캠프) > AI 모델 활용 백엔드 개발 과정' 카테고리의 다른 글
| [HTML] 24.01.26 HTML 기본 및 태그 (0) | 2024.01.29 |
|---|---|
| [GPT] 24.01.25 GPT 프롬프트 및 API 실습 (2) | 2024.01.25 |
| [머신러닝] 24.01.24 머신러닝 실습 (0) | 2024.01.24 |
| [머신러닝] 머신러닝 개요 (0) | 2024.01.23 |
| [Python] 24.01.22 Pandas (0) | 2024.01.22 |



