
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 인공신경망
- Keras
- 맴버연산자
- choice
- gitmoji
- 구글코랩
- mnist
- built-in function
- Next.js
- 깃모지
- f-string
- 정적 메서드
- 메서드
- 캐시의 지역성
- cache locality
- 메서드채이닝
- 추상 클래스
- ITER
- randrange
- neural network
- __init__
- Colab
- nextjs
- self
- class
- 비공개 속성
- 식별연산자
- PYTHON
- 정수
- 실수
- Today
- Total
IT world
[Python] 24.01.05 리스트, 튜플, 딕셔너리, 셋 본문
1. 리스트
가변적(mutable)이고, 순서가 있는 시퀀스 자료형
위치의 특성을 가지고 있어 정렬할수 있으며, 가변적이라는 특성 때문에 리스트 내의 원소들은 생성 후에도 변경, 추가, 삭제가 가능하다.
문자열은 불변이지만 리스트는 항목의 변경이 가능하며, 다양한 자료형을 함께 담을 수 있고, 리스트 안에 또 다른 리스트를 담아서 다차원 리스트를 구성할 수 있다.

1.1 리스트의 연산
- 덧셈 : 리스트를 연결
- 곱셈 : 리스트를 여러번 반복 (중첩되지 않은 리스트의 곱셈은 값이 하나가 변경이 되어도 다른 값들이 변경이 되지 않는다)
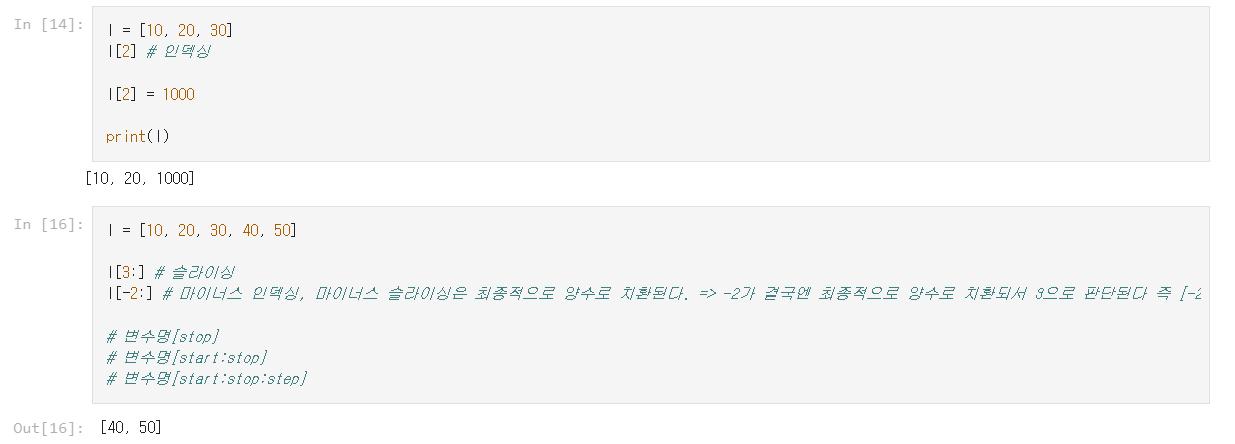
1.2 리스트 인덱싱
문자열처럼 순서가 있어 인덱싱을 통해 각 항목에 접근 가능.
리스트는 문자열과 마찬가지로 0부터 인덱싱을 시작하고 순서가 있는 시퀀스형 자료형의 공통적인 특징이다.
1.3 리스트 슬라이싱
일 부분을 추출하고 싶을 때에는 인덱스를 사용하여 잘라 냄.
[start:stop:step] 형태로 사용하며, 마찬가지로 step은 기본적으로 1이며 생략할 수 있다.
1.4 리스트 메모리 구조
리스트는 연속된 메모리 공간에 원소들을 저장하지 않는다. 각 원소들은 참조를 통해 다양한 위치에 저장된 객체를 가리키고, 이러한 구조 때문에 리스트는 다양한 타입의 데이터를 동시에 저장할 수 있다.
파이썬에서 모든 것은 객체로 취급하며 리스트의 각 요소는 실제 데이터 값을 직접 저장하는 것이 아니라, 해당 객체를 참조하는 주소를 저장
아래 그림에서 리스트는 각 요소에 대한 참조(주소)를 저장하고, 그 참조를 통해 실제 메모리 위치를 찾아가면 1, 10, apple, 3.14와 같은 실제 값을 저장하는 객체들이 있다.

파이썬 리스트 메모리 구조의 장점은 다양한 데이터 타입의 원소를 동일한 리스트에 저장할 수 있다는 것과 데이터의 추가 및 삭제가 다른 언어에 비해 비교적 효율적이라는 점이다.
단점으로는 참조를 저장하기 위한 추가적인 메모리가 필요하다는 점과, 데이터가 연속적인 메모리 공간에 저장되지 않아
캐시의 지역성(cache locality)이 떨어진다는 점이다.
* 캐시의 지역성(cache locality) 컴퓨터의 메모리는 여러 계층으로 구성되어 있고 이 중에서 CPU에 가장 가까운 메모리를 캐시 메모리라고 한다. 이 캐시 메모리는 매우 빠르지만 용량이 작다. 컴퓨터가 빠르게 데이터에 접근하려면 그 데이터가 가까운 곳에 모여 있어야 한다. 캐시 지역성은 데이터가 얼마나 가까이 모여 있는지를 나타내며 파이썬 리스트는 메모리가 모여있지 않기 때문에, 때로는 느릴 수 있다.
1.5 리스트 메서드
- append() : 리스트의 끝에 값을 추가
- cleart() : 리스트 모든 항목 삭제
- copy() : 얕은 복사 → 동일한 값을 가진 새로운 리스트를 반환
- count() : 특정 값이 리스트에 몇 번 포함되어 있는지 확인
- extend() : 다른 리스트나 순회 가능한(iterable) 항목들을 추가
- index() : 해당 값의 인덱스를 반환
- insert() : 해당 인덱스에 값 추가
- pop() : 해당위치의 값을 반환하고 리스트에서 삭제
- remove() : 해당 값이 첫번째로 발견되는 위치의 값을 삭제
- reverse(), reversed() : 순서를 뒤집는다.
- sort(), sorted() : 리스트를 정렬한다.
2. 튜플
가변적(mutable)이고, 순서가 있는 시퀀스 자료형으로 내부의 참조 변경이 불가능하다.
변경되서는 안되는 데이터를 보호하거나 값이 바뀌면 안되는 경우에 사용되며, 리스트에 비해 처리속도가 조금 더 빠르다.
튜플의 가장 큰 특징 중 하나는 불변성(immutable)
2.1 튜플의 연산
- 덧셈 : 두 튜플을 연결
- 곱셈 : 튜플을 여러번 반복
2.2 튜플 인덱싱
순서가 있는 시퀀스 자료형이기 때문에 인덱싱을 통해 각 항목에 접근 가능.
2.3 튜플 슬라이싱
슬라이싱을 사용하여 부분적인 값을 추출할 수 있다.

3. 딕셔너리
비유로 하자면 사전 같은 자료형, 순서가 없는 자료형이었으나, Python 3.6 버전 이상부터는 순서가 보장된다.
키(key) : 값(value) 쌍의 형태로 정보를 저장하고, key를 기준으로 찾기 때문에 key는 유일해야하며, 특정 정보를 빠르게 찾거나 접근이 가능하다.

3.1 딕셔너리 메서드
- clear() : 딕셔너리의 모든 키-값 쌍을 삭제
- copy() : 딕셔너리의 얕은 복사를 반환
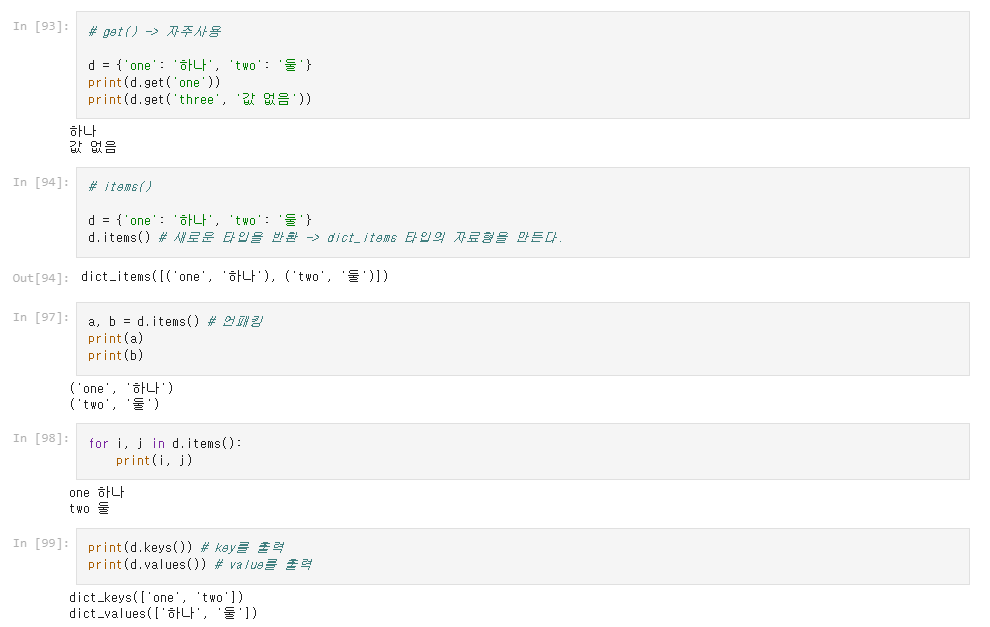
- get() : 키에 접근 시 에러 없이 값을 추출(해당 키가 없을 경우 None을 반환하지만 인자에 값을 넣어 기본값 반환 가능)
- items() : 키와 값을 쌍으로 추출
- keys() : 딕셔너리의 모든 키를 추출
- values() : 딕셔너리의 모든 값을 추출
- popitem() : 딕셔너리의 마지막 키-값 쌍을 반환하고 그 항목 삭제
- setdefault() : 해당 키에 대한 값을 반환. 키가 없으면 기본값을 설정하고 반환
4. 셋
셋은 집합의 순서가 없으며, 중복 값을 허용하지 않는다.
데이터 중복을 제거하는데 매우 유용하고, 집합 연산을 사용하여 두 그룹의 유사성이나 차이점을 빠르게 파악할 수 있다.
4.1 셋 연산
- 합집합 (union)
- 교집합 (intersection)
- 차집합 (difference)

'모두의 연구소(오름캠프) > AI 모델 활용 백엔드 개발 과정' 카테고리의 다른 글
| [Python] 24.01.09 조건문과 반복문 (0) | 2024.01.10 |
|---|---|
| [Python] 24.01.08 파이썬의 함수, Parameter, Argument 그리고 지역/전역 변수 (0) | 2024.01.10 |
| [Python] 24.01.04 파이썬 연산자와 시퀀스 자료형 (0) | 2024.01.09 |
| [Python] 24.01.03 파이썬 자료형과 형변환 그리고 연산자 (2) | 2024.01.04 |
| [Python] 24.01.02 Random 함수와 파이썬 자료형 (1) | 2024.01.03 |



