
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 캐시의 지역성
- neural network
- 깃모지
- Keras
- Colab
- 비공개 속성
- nextjs
- 실수
- built-in function
- ITER
- 메서드채이닝
- 메서드
- class
- 정적 메서드
- gitmoji
- 인공신경망
- Next.js
- f-string
- self
- 추상 클래스
- 식별연산자
- 정수
- mnist
- 맴버연산자
- randrange
- PYTHON
- choice
- cache locality
- 구글코랩
- __init__
- Today
- Total
IT world
[머신러닝] 머신러닝 개요 본문
머신러닝(Machine Learning)
머신러닝이란? 인공지능의 한 분야로, 데이터 안에서 패턴(규칙)을 찾아내어 학습하고 결과를 예측하는 분석 방법.
인간이 학습을 통해 정확도를 점진적으로 개선하는 방식을 모방한 알고리즘으로 인간의 학습능력과 같은 기능을 컴퓨터에 부여하기 위한 기술이다.
컴퓨터가 스스로 학습할 수 있도록 도와주는 알고리즘을 개발하는 분야로, 데이터를 분석하고 분석 결과를 스스로 학습한 후 이를 기분으로 어떠한 판단이나 예측을 하는 것을 의미한다. 따라서 머신러닝에서는 양질의 데이터가 매우 중요한 역할을 하며, 양질의 데이터를 많이 보유할수록 보다 높은 성능을 이끌어 낼 수 있다.

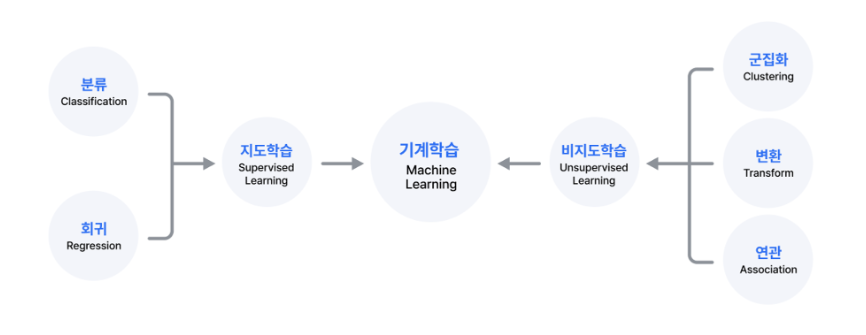
머신러닝은 다양한 알고리즘 기법을 적용하는 어려 유형의 모델로 구성되며, 크게 지도학습, 비지도학습, 강화학습으로 분류된다. 지도학습은 입력 데이터와 출력(정답) 데이터가 존재하는 경우 사용되며 비지도학습은 출력(정답) 데이터가 존재하지 않는 경우에 사용되고 강화학습은 시행착오를 통해 보상을 최대화하는 방향으로 학습하는 방법이다.
머신러닝은 데이터 마이닝(data mining), 예측 분석(predictive analytics), 패턴 인식(pattern recognition) 등 다양한 분야에서 활용된다.
지도학습(Supervised learning)
지도 학습은 훈련 데이터(입,출력 데이터)를 통해 훈련하며 정답이 있는 데이터를 활용해 학습하기 때문에 입력값(X data)이 주어지면 입력값에 대한 정답(라벨: Y data)을 데이터에 지정해주어야한다.
- 입력값(X)과 결과값(정답 레이블)(Y)을 같이 주고 학습 시키는 방법 → 이를 통해 모델이 학습하여 새로운 입력데이터에 대한 출력을 예측
- 예로 정답을 알고 있는 엄마가 아이에게 말을 가르치는 것처럼, 정답을 기반으로 오류를 줄여서 학습하는 방법(반복 학습을 통해 오류를 줄여가면서 점차 정답에 가까워 지는 방법)
- 대표적인 알고리즘 : 분류(Classification), 회귀(Regression)
1. 분류(Classification) : 데이터가 범주형 변수를 예측하기 위해 사용될때 → 이미지에 강아지나 고양이와 같은 레이블을 할당하는 경우에 해당
- 이진 분류 : 레이블이 두 개인 경우 → Q. 이 글은 스팸이야? A. True / False 결과
- 다중 분류 : 범주가 두 개 이상인 경우 → Q. 이 동물은 뭐야? A. 고양이 또는 사자 또는 강아지등으로 분류
2. 회귀(Regression) : 어떤 데이터들의 특징(feature)을 토대로 값을 예측하는 것. 트레이닝 데이터를 이용하여 연속적인 값을 예측하는 것 → Q. 어디 동네에 어떤 평수 아파트면 집 값은? A. 어디 동네에 x평이면 얼마야
비지도학습(Unsupervised Learnging)
비지도 학습은 정답 라벨이 없는 데이터를 비슷한 특징끼리 훈련을 통해 군집화하여 새로운 데이터에 대한 결과를 예측하는 방법. 모델이 입력 데이터를 학습한 다음 관련성이 있고 학습 가능한 데이터 모두를 사용해 패턴과 상관관계를 인식한다. 정답이 없는 데이터로부터 패턴이나 형태를 찾아야 하기 때문에 데이터의 양과 질이 중요하다.
- 지도 학습과 달리 정답을 알려주지 않고 예측하는 방법
- 입력데이터(X)만 제공되며, 모델은 데이터의 숨겨진 패턴이나 구조를 찾아내는데 사용
- 정답을 모르더라도 유사한 것들과 서로 다른 것들을 구분해서 군집을 만들 수 있는 학습 방법
- 안면 인식, 시장조사, 사이버보안 등 사용
1. 군집(Clustering) : 서로 유사한 정도에 따라 다수의 객체를 군집으로 나누는 작업. (유사도가 높은 데이터 끼리 그룹화)
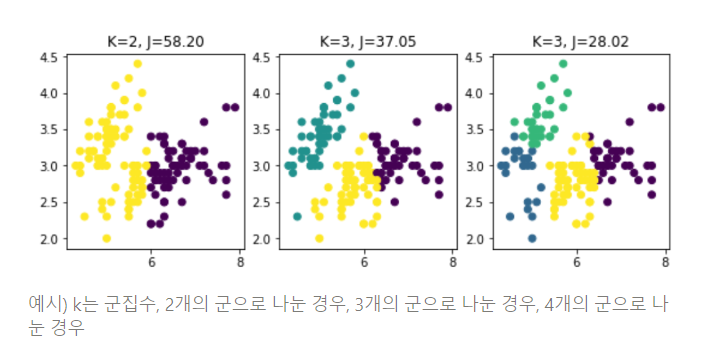

미신 러닝 실습
1. 데이터 import
- sklearn 라이브러리를 이용하여 타이타닉 승객 정보의 데이터셋을 불러온다.
from sklearn.datasets import fetch_openml
# fetch_openml을 사용하여 타이타닉 데이터셋을 불러옵니다.
titanic = fetch_openml('titanic', version=1, as_frame=True)
# 데이터 프레임으로 변환
titanic_data = titanic.frame
2. 데이터 확인
# 데이터의 처음 5행을 출력하여 데이터를 살펴봅니다.
print(titanic_data.head())
# 데이터셋의 통계적 요약을 출력합니다.
print(titanic_data.describe())
# 결측치가 있는지 확인합니다.
print(titanic_data.isnull().sum())
3. 데이터 전처리
- 결측치를 처리하는 방법에는 결측치를 평균값이나 중앙값으로 대체하거나, 해당 행 또는 열을 전체적으로 제거할 수 있다.
import pandas as pd
# ['age']변수의 평균값으로 null값을 채워라
# fillna : 특정한 어떤 값으로 na를 채운다. -> age열에 결측치를 age의 평균값으로 채워 넣고 기존 데이터에 업데이트(inplace=True)
titanic_data['age'].fillna(titanic_data['age'].mean(), inplace=True)
# ['sex']변수의 값을 변경 -> male=0, female=1로 값 변경 -> 숫자로 변경해서 활용하는게 좋음
titanic_data['sex'] = titanic_data['sex'].map({'male': 0, 'female': 1})
# 사용하지 않는 값들에 대해서는 삭제 -> 현재 예시에서는 해당 컬럼들을 사용하지 않을 것이기 때문에 제외
titanic_data = titanic_data.drop(['name', 'ticket', 'cabin', 'embarked', 'boat', 'body', 'home.dest'], axis=1)
위 코드에서 age 컬럼에는 많은 결측치가 존재하는 것을 확인할 수 있다. titanic_data['age'].fillna(titanic_data['age'].mean(), inplace=True) 이 문장에서 ['age'] 변수의 결측치 값을 age의 평균값으로 수정한다. 하지만 해당 처리에도 선택이 필요하다..
1300개의 데이터 중 250개가 결측치라면?
첫번째, 데이터 제거 시 약 20%의 데이터 손실이 발생한 것이고 이는 모델 성능이 떨어질 수 있는 원인이다.
두번째, 데이터 대체 시 값을 잘 모르는 상태에서 해당 값을 살린다면, 1300개를 온전히 사용할 수 있으니 데이터 자체는 확보된 것이지만 신빙성이 떨어질 수도 있다.
따라서 준지도 학습을 활용하는것도 좋을 것이고 모델을 사용할 때 항상 어떤 모델이 좋을 지 판단해야한다.
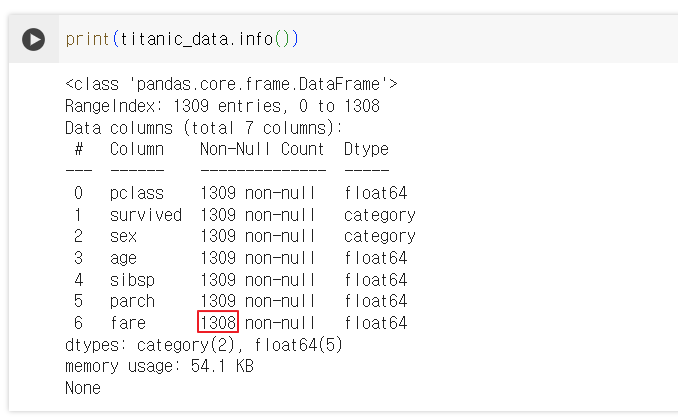
그럼에도 결측치가 존재하는 컬럼이 있어 해당 컬럼의 결측치도 평균값으로 채웠다.
이처럼 전처리 작업은 너무 중요하고, 정확한 데이터를 위한 방안을 생각해야한다.
4. 데이터 분할
- 데이터셋을 훈련 세트와 테스트 세트로 나눈다.
이 과정은 모델의 성능을 객관적으로 평가하기 위해 필요하며, 데이터를 무작위로 나누어 일부는 모델 학습에 사용하고, 나머지는 모델의 성능을 테스트하는 데 사용한다.
from sklearn.model_selection import train_test_split
# 입력 변수와 타겟 변수 분리
X = titanic_data.drop(['survived'], axis=1) # 'survived' 컬럼 제외
y = titanic_data['survived'] # 타겟 변수
# 데이터 분할: 훈련 세트 80%, 테스트 세트 20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
위 코드 처럼 x, y 데이터를 만든 후 훈련 데이터와 테스트 데이터를 각각 80%, 20%로 데이터를 분할했다.
5. 알고리즘 선택
- 머신러닝의 알고리즘 중 하나인 sklearn의 랜덤 포레스트를 사용.
from sklearn.ensemble import RandomForestClassifier
# 랜덤 포레스트 분류기 인스턴스 생성
model = RandomForestClassifier(random_state=42)
6. 학습
- 모델을 훈련 데이터에 맞추어 학습 시킨다.
model.fit(X_train, y_train)
7. 예측
- 학습된 모델로 테스트 데이터에 대한 예측을 수행
predictions = model.predict(X_test)
예측 결과로는 0과 1을 반환했으며, 살아남은 사람은 1로 출력된다.
8. 평가
- 정확도를 확인할 것이며, 실제 값과 예측값을 비교하여 두 데이터 얼마나 일치하는지 판단하는 정확도 검사이다.
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy}")
# [출력결과] 정확도 : 0.7862595419847328
여기선 두가지 방법을 선택할 수 있다.
첫번째, 78%라는 정확도가 마음에 들지 않고 90%까지 올려야겠다고 판단한다면(자의적이든 타이적이든) EDA(전처리)로 다시 돌아가 처음부터 다시 진행한다.
두번째, 해당 정확도와 모델의 성능에 만족하니 하이퍼파라미터 튜닝을 진행한다.
보통 첫번째 전처리로 돌아가 여러번 진행한 후에 두번째 작업을 진행한다.
중요한 변수라고 판단되는 내용을 출력하여 확인할 수 있다.
# 해당 변수가 얼마나 중요한지 그래프로 확인
# 중요도가 얼마나 되는지 확인한다.
import matplotlib.pyplot as plt
# 변수 중요도 추출
feature_importances = model.feature_importances_
# 변수 이름과 중요도를 매핑
feature_names = X_train.columns
feature_importance_dict = dict(zip(feature_names, feature_importances))
# 중요도에 따라 변수 정렬
sorted_importance = sorted(feature_importance_dict.items(), key=lambda x: x[1], reverse=True)
# 중요도 시각화
plt.figure(figsize=(10, 8))
plt.barh([item[0] for item in sorted_importance], [item[1] for item in sorted_importance])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importances in Random Forest Model')
plt.gca().invert_yaxis() # 높은 중요도가 위로 오게 정렬
plt.show()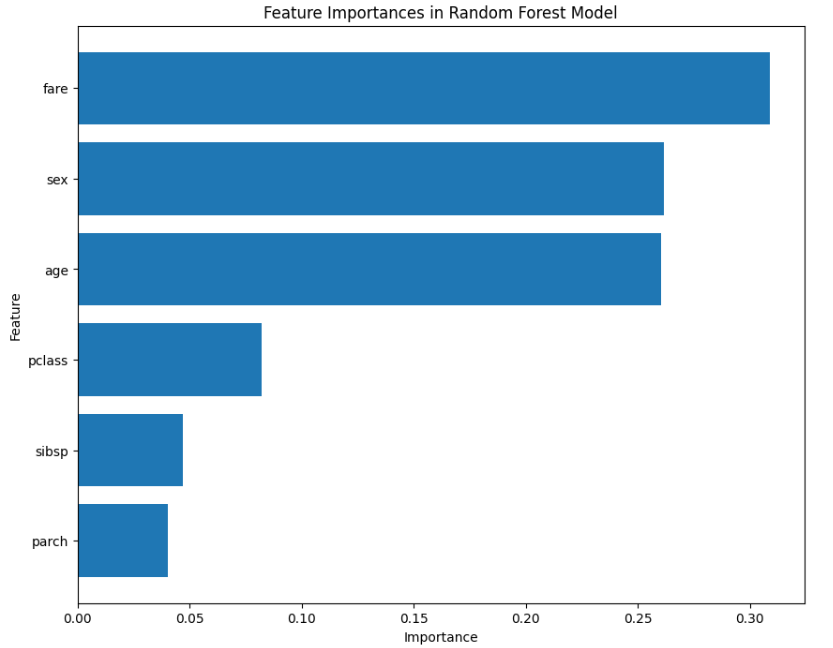
9. 튜닝
- 모델의 하이퍼파라미터를 조정하여 성능을 개선하는 작업.
기존 모델의 성능을 개선하기 위한 작업으로 무조건 성능이 개선되는건 아니며, 성능 개선 작업을 해보고 기존 모델과 정확도 비교하여 사용 모델을 판단한다.
from sklearn.model_selection import GridSearchCV
param_grid = {'n_estimators': [50, 100, 200], 'max_depth': [5, 10, 20]}
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 테스트 데이터를 가지고 predict(예측)한다.
predictions_grid = grid_search.predict(X_test)
# 재평가
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, predictions_grid) #실제값과 예측값을 비교해줘
print(f"Accuracy: {accuracy}") # 두 데이터가 얼마나 일치하는지 점검
# [출력결과] 정확도: 0.7748091603053435
머신러닝 사용 시 고려해야할것
- 기존보다 성능이 좋아졌는가? (중요) → 무엇을 하던간에 기존보다 좋아야! 성과!
- 변수 중요도는 고르게 잘 구성되어있는가?
- 새로운 변수로 사용할만한 것은 없는가?
- 모델 비교는 충분하게 했는가?
- 과적합을 발생하지 않았는가?(중요) → 학습된 데이터만 잘 맞추는 현상
- Train과 Test간 성능차이가 10% 이상 차이는 나지 않는가?
- 모델에 대한 설명이 가능한가?
추가로 선형 회귀, 로지스틱 회귀, 오즈비에 대해 배웠다. 머신러닝에 대해서는 예전 프로젝트를 진행할 때 학습했던 내용이 기억이 남아 크게 어렵진 않았지만 강사님과 설명은 너무 좋았는데 회귀분석내용은 나에겐 어려운 부분이라 추가로 복습이 필요할 것 같아, 충분히 복습과 실습을 해본 후에 다시 작성해야할 것 같다..
'모두의 연구소(오름캠프) > AI 모델 활용 백엔드 개발 과정' 카테고리의 다른 글
| [딥러닝] 24.01.24 딥러닝 실습 (0) | 2024.01.24 |
|---|---|
| [머신러닝] 24.01.24 머신러닝 실습 (0) | 2024.01.24 |
| [Python] 24.01.22 Pandas (0) | 2024.01.22 |
| [Python] 24.01.18 기타 내용과 정규표현식 (0) | 2024.01.18 |
| [Python] 24.01.17 함수 심화(2)와 모듈에 대해서 (0) | 2024.01.17 |



