
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- neural network
- PYTHON
- built-in function
- 깃모지
- 정수
- Next.js
- 추상 클래스
- 캐시의 지역성
- 메서드
- 메서드채이닝
- Colab
- mnist
- __init__
- nextjs
- 비공개 속성
- 맴버연산자
- 구글코랩
- self
- class
- choice
- 식별연산자
- f-string
- 실수
- 정적 메서드
- cache locality
- randrange
- gitmoji
- 인공신경망
- ITER
- Keras
- Today
- Total
IT world
[머신러닝] 24.01.24 머신러닝 실습 본문
오전에는 어제 배운 머신러닝을 복습하는 시간을 가졌다.
데이터 셋은 kaggle의 winequality csv 파일을 사용하여 실습을 진행했다.
1. 데이터 호출
필요한 패키지를 호출하고, 와인 퀄리티 데이터 셋을 호출했다.
# 기본 패키지 모음
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 전처리 및 모델링 준비를 위한 패키지
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
# 실제 모델링을 위한 패키지
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
# 모델 평가를 위한 패키지
from sklearn.metrics import classification_report
from sklearn import metrics
# 다운받은 데이터를 코랩에서 불러오겠습니다.
wine = pd.read_csv('/content/winequality_red.csv')
wine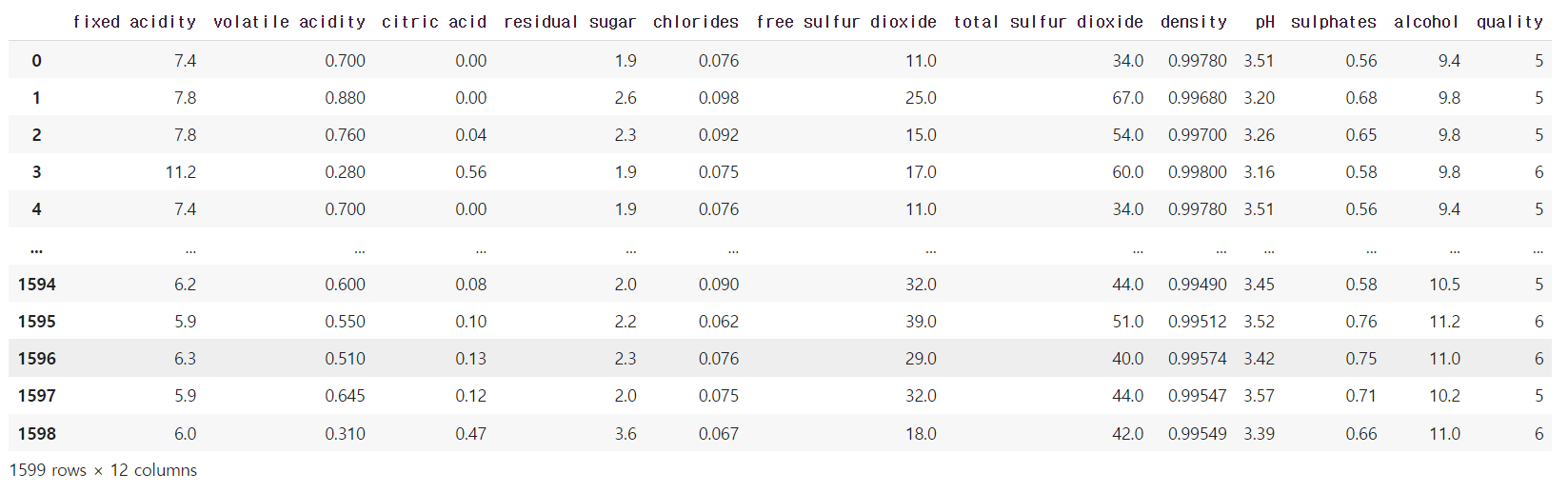
2. 데이터 탐색
특성별 quality와 관계를 시각화하여 정보를 표현
sns.countplot(x='quality', data=wine)
# 특성별도 데이터를 시각화 하여 데이터에 대한 정보를 파악합니다
df1 = wine.select_dtypes([int, float])
for i, col in enumerate(df1.columns):
plt.figure(i)
sns.barplot(x='quality', y =col, data=df1)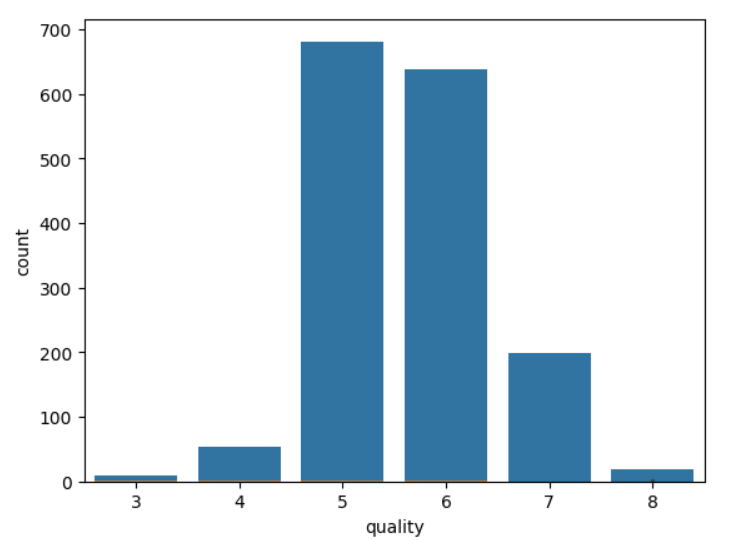
해당 데이터에서는 와인의 품질이 0~10까지 품질평가가 이루어졌고, 데이터는 최소 3부터 최대 8점까지 존재한다.
해당 예시는 품질이 좋은지, 나쁜지를 확인하는 것으로 이진분류로 전처리를 진행 했다.
# 6.5점을 기준으로 좋은 와인과 나쁜 와인을 구분하겠다고 선언
bins = (2, 6.5, 8)
group_names = ['bad', 'good']
wine['quality'] = pd.cut(wine['quality'], bins = bins, labels = group_names)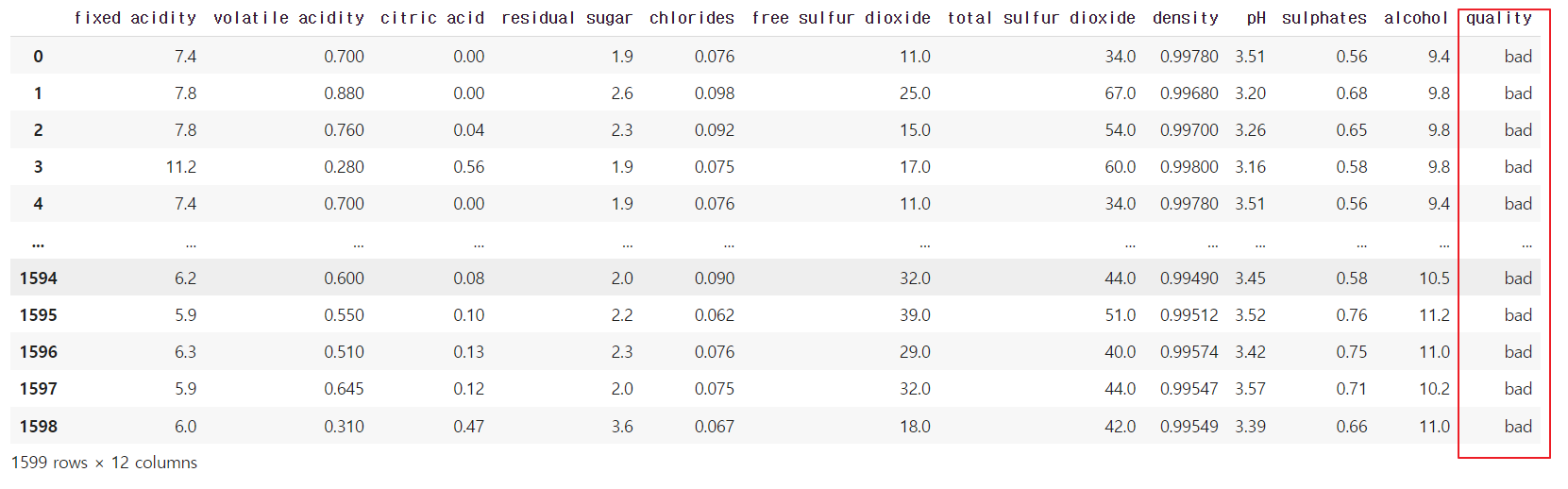
6.5점을 기준으로 품질을 좋음과 나쁨으로 나누었다. 하지만 컴퓨터 관점에서 풀기 위해 0과 1로 다시 나눠있다.
# Good/Bad는 인식할 수 없음. 따라서 이를 인식할 수 있도록 Label Encoding을 실시
label_quality = LabelEncoder()
wine['quality'] = label_quality.fit_transform(wine['quality'])
# 1: 좋음 , 0: 나쁨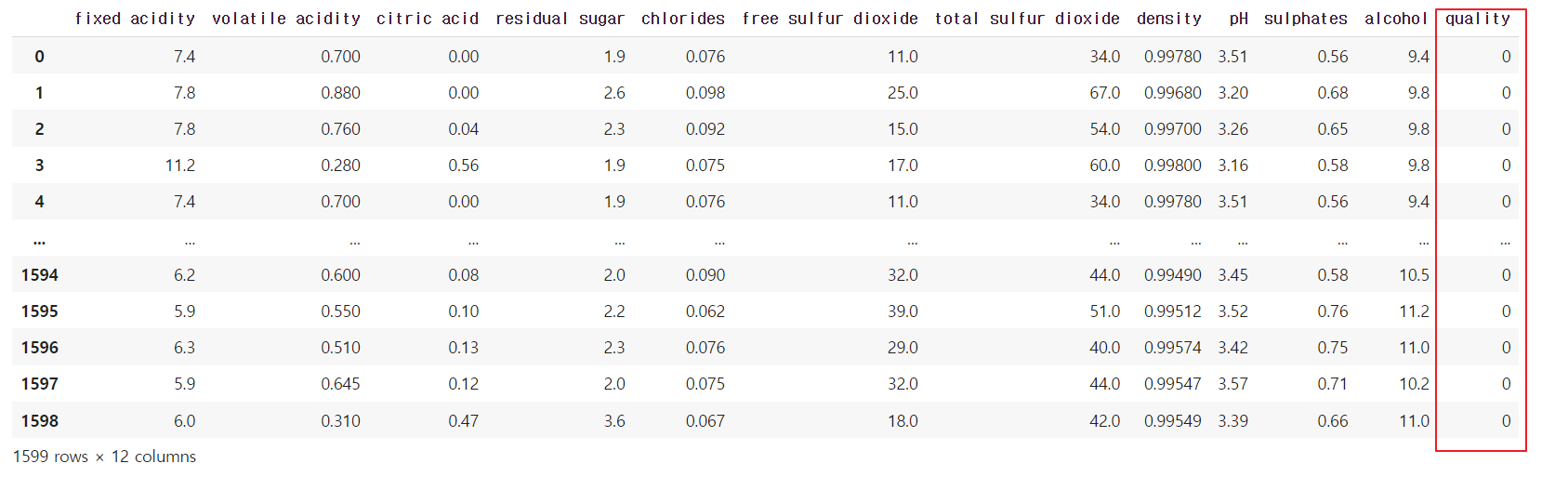
확인 결과 217개의 와인이 품질이 좋고, 1382개의 품질이 나쁜 와인이 있는 것을 확인하였다.
# 종속변수와 독립변수를 나누어주는 작업
x = wine.drop('quality', axis = 1)
y = wine['quality']
# 변수별로 Train과 Test 쓸 데이터 셋을 분류x
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
# 측정 지표의 표준화.
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.fit_transform(x_test)
3. 모델 학습
어떤 모델의 정확도가 높은지 확인하기 위해 몇가지 모델을 통해 각각의 정확도를 확인했다.
- Logistic Regression
- Support Vector Machine
- KNN
- Naive Bayesian
- Decision Tree
- Random Forest
# 각각의 모델 학습
# 로지스틱 회귀
model = LogisticRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
# SVC
model_svc = SVC()
model_svc.fit(x_train, y_train)
y_pred_svc = model_svc.predict(x_test)
# KNN
model_knn = KNeighborsClassifier(5)
model_knn.fit(x_train, y_train)
y_pred_knn = model_knn.predict(x_test)
# NB
model_NB = GaussianNB()
model_NB.fit(x_train, y_train)
y_pred_NB = model_NB.predict(x_test)
# Decision Tree
model_tree = tree.DecisionTreeClassifier()
model_tree.fit(x_train, y_train)
y_pred_tree = model_tree.predict(x_test)
# RandomForest
model_rfc = RandomForestClassifier(n_estimators=200)
model_rfc.fit(x_train, y_train)
y_pred_rfc = model_rfc.predict(x_test)
각각의 모델들을 학습한 후 모델들의 정확도를 비교.
print("Logistic Regression Accuracy:", metrics.accuracy_score(y_test, y_pred))
print("Support Vector Machine Accuracy:", metrics.accuracy_score(y_test, y_pred_svc))
print("KNN Accuracy:", metrics.accuracy_score(y_test, y_pred_knn))
print("Gausian NB Accuracy:", metrics.accuracy_score(y_test, y_pred_NB))
print("Decision Tree Accuracy:", metrics.accuracy_score(y_test, y_pred_NB))
print("Random Forest Accuracy:", metrics.accuracy_score(y_test, y_pred_rfc))
acc_df = pd.DataFrame({'classifier':
['Logistic Regression ',
'Support Vector Machine',
'KNN',
'Gausian NB',
'Decision Tree',
'Random Forest'],
'accuracy':
[metrics.accuracy_score(y_test, y_pred),
metrics.accuracy_score(y_test, y_pred_svc),
metrics.accuracy_score(y_test, y_pred_knn),
metrics.accuracy_score(y_test, y_pred_NB),
metrics.accuracy_score(y_test, y_pred_tree),
metrics.accuracy_score(y_test, y_pred_rfc),
]
})
acc_df
결정트리 모델
결정트리 모델이란? 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리(Tree) 기반의 분류 규칙을 만드는 것.
의사결정 트리라고도 하며 스무고개 하듯 예/아니오 질문을 이어가듯 특정 기준(질문)에 따라 데이터를 구분하는 모델이다. 다만 학습성능을 과도하게 학습시킬 경우 너무 복잡한 규칙구조를 가질수도 있고, 과적합이 발생할 가능성이 높다.
하나의 모델이 복잡한 규칙을 가지고 과적합의 문제를 해결하기 위해 앙상블 기법이 등장했고, 결정트리에서 앙상블 기법으로 보완한 것이 랜덤 포레스트 모델이다.
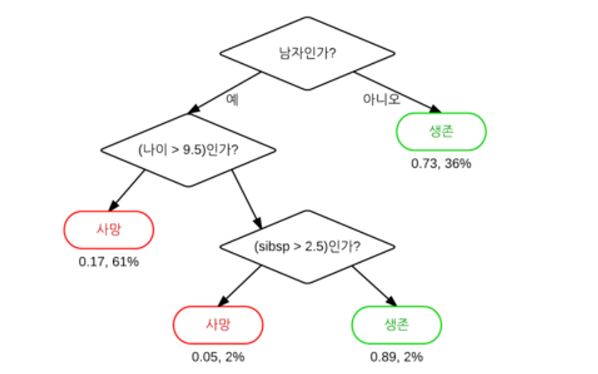
결정트리는 직관적이고, if-else 문법과 같은 조건문이 무수하게 많이 모여있는 모델이라고 생각하면 된다.

결정트리 예제
표준화 되지 않은 데이터를 시각화해봤다.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
from sklearn.tree import DecisionTreeClassifier
# 종속변수와 독립변수를 나누어주는 작업
x = wine.drop('quality', axis = 1)
y = wine['quality']
# 변수별로 Train과 Test 쓸 데이터 셋을 분류x
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 42)
dt = DecisionTreeClassifier(random_state = 2023)
dt.fit(x_train, y_train)
# 시각화
plt.figure(figsize =(10,7))
plot_tree(dt)
plt.show()
무수한 숲의 형태의 트리가 만들어졌고, 처음 단계를 나누는 작업을 확인하기 위해 코드를 다시 작성했다.
plt.figure(figsize =(10,7))
plot_tree(dt, max_depth = 1, filled = True)
plt.show()
첫번째의 단계를 확인해봤을 때 읽는 방법은
- 조건 → 구분되는 조건
- 불순도(gini) → 데이터 집합의 불순도 측정
- 총 샘플수(samples) → 총 데이터 수(1109 + 170 = 1279)
- 클래스별 샘플(value) → 구분별 데이터 수(나쁜 술: 1190, 좋은 술: 170)
알코올이 11.55를 기준으로 좋은 술인지 아닌지를 조건을 확인했고 왼쪽으로 1109개, 오른쪽으로 170개 구분된다. Target이 1인 좋은 술이 170개로 나뉜 것을 볼 수 있고 그 아래도 마찬가지로 조건에 의해 지속적으로 학습하게 된다.
지니 불순도는 0에 가까울수록 데이터 분포가 균일하고 0.5에 가까울수록 불균형에 가깝다.
제곱 계산식은 클래스/전체의 값의 제곱을 실시하면 되고 100 - 제곱값들의 합이 지니 계수가 된다.

'모두의 연구소(오름캠프) > AI 모델 활용 백엔드 개발 과정' 카테고리의 다른 글
| [GPT] 24.01.25 GPT 프롬프트 및 API 실습 (2) | 2024.01.25 |
|---|---|
| [딥러닝] 24.01.24 딥러닝 실습 (0) | 2024.01.24 |
| [머신러닝] 머신러닝 개요 (0) | 2024.01.23 |
| [Python] 24.01.22 Pandas (0) | 2024.01.22 |
| [Python] 24.01.18 기타 내용과 정규표현식 (0) | 2024.01.18 |



